
With audio models on Scenario, you can create professional-quality speech, music, sound effects, and lip-sync animation, all from simple text prompts.
Scenario offers a comprehensive ecosystem for all your audio needs, from generating expressive voiceovers and cinematic music to designing custom sound effects and animating characters with realistic lip-sync.
In the following sections, we’ll walk through each of these capabilities in detail, exploring the various audio models, their unique features, and best practices for achieving high-quality results.
Text-to-Speech
Giving Your Creations a Voice
Scenario’s text-to-speech tools let you turn any line of text into natural, expressive voiceover. You can choose from multiple models, including ElevenLabs models or Minimax Speech, each offering unique voices and language options. Start by typing the text you want to hear spoken, this will become the voiceover audio. Depending on the model, choose your voice settings like voice ID, stability, or speed, and generate clean, production-ready speech.
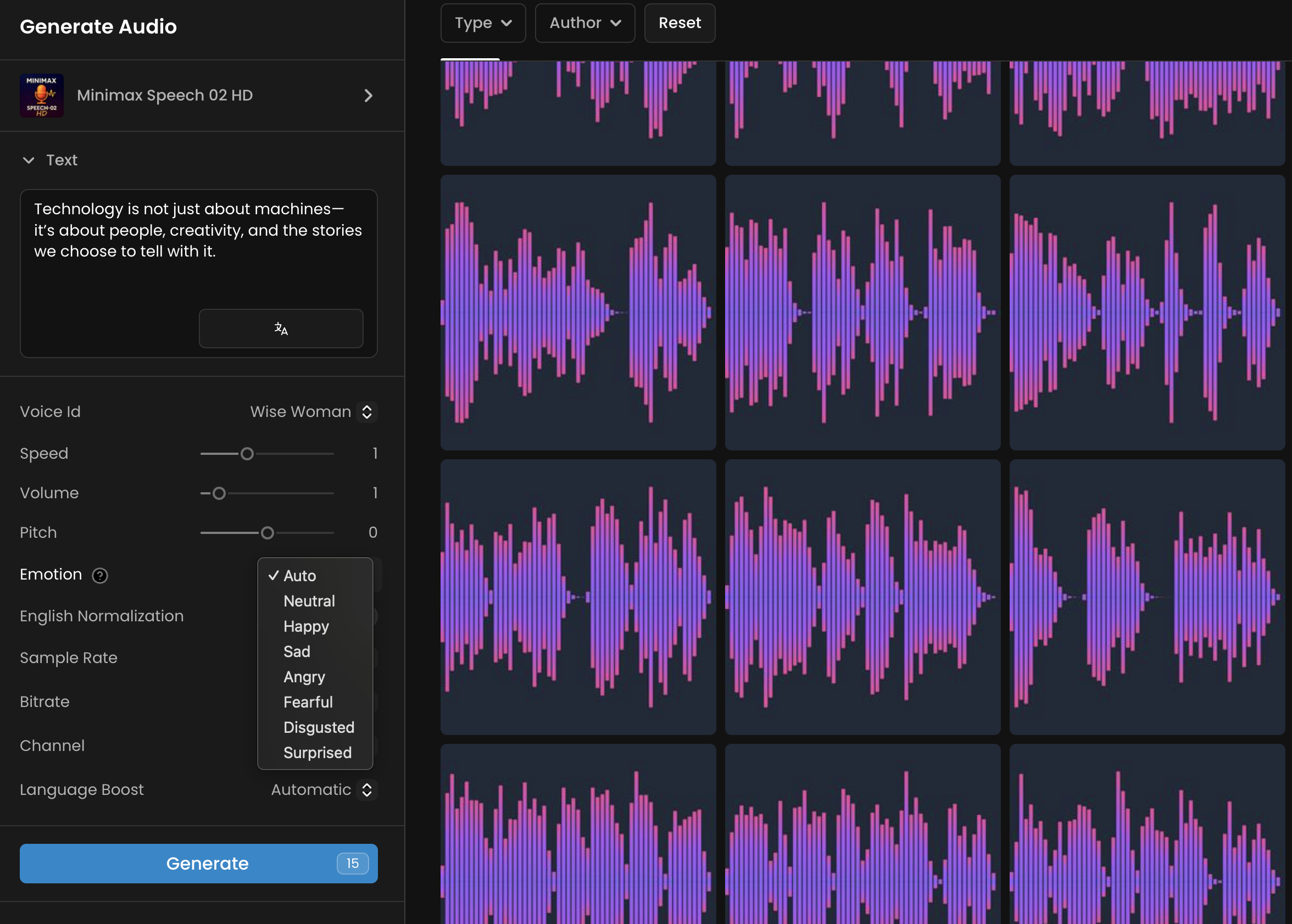
Minimax Speech 02 HD/Turbo
Minimax Speech 02 offers creators the ability to generate high-quality, natural-sounding speech from text input. Built on Minimax's cutting-edge neural architecture, Minimax Speech 02 excels at producing human-like vocal performances with precise control over voice characteristics, emotional expression, and audio quality. The model supports multiple languages and voice personalities. More on this section
Key Features:
Granular Voice Control
Minimax Speech 02 provides extensive control over the generated voice. You can select from a diverse range of voice personalities, each with distinct characteristics and speaking styles. Options include professional voices like "Wise_Woman" and "Elegant_Man," casual personalities like "Friendly_Person" and "Casual_Guy," and specialized voices like "Young_Knight" and "Inspirational_girl."
Emotional Expression
You can select from emotional states including neutral, happy, sad, angry, fearful, disgusted, and surprised. The "auto" setting allows the model to interpret emotional context from the text content. Each emotion affects not just tone but also pacing, emphasis, and vocal inflection patterns.
Audio Quality Configuration
Minimax Speech generates high-quality audio with configurable sample rates up to 44100 Hz and bitrates up to 256000 kbps. You can also select between mono and stereo output.
ElevenLabs
ElevenLabs offers powerful text-to-speech models in Scenario: ElevenLabs v3, Multilingual v2 and Turbo 2.5. Multilingual v2 focuses on emotional richness and natural speech quality across 29 languages, making it ideal for audiobooks, film dubbing, and narrative content. Turbo 2.5 prioritizes speed and low latency for real-time applications, supporting 32 languages with significantly faster generation times, making it perfect for conversational AI and interactive applications. More on this section
Key Features:
Extensive Language Support
All models support a wide range of languages, with Turbo 2.5 offering support for 32 languages, including Vietnamese, Hungarian, and Norwegian.
Voice Library
You can choose from a diverse library of voices, each with its own unique characteristics. These voices work with both models, allowing for consistent voice characteristics across different languages and applications.
Advanced Controls
All Elevenlabs models offer advanced controls for fine-tuning the generated speech, including Stability, Similarity Boost, Style Exaggeration, and Speed. Turbo 2.5 also offers manual language enforcement with Language Code support.
Text-to-Music
Composing Original Soundtracks
Scenario supports leading text-to-music models like Meta MusicGen and Google Lyria 2, both capable of generating original music based on a simple prompt. All you need to do is describe the mood, genre, or feeling you want. From ambient sounds for gameplay to musical scores for launch videos and ads, the results are tailored to your prompt and ready to drop into your video or scene.
Meta MusicGen
Meta MusicGen offers creators great control over musical composition through both text prompts and melody conditioning. Developed by Meta's research team, MusicGen excels at generating high-quality, coherent musical pieces that can span various genres, styles, and emotional contexts. More on this section
Key Features:
Dual-Input Capability
MusicGen can generate music from text descriptions alone or use reference audio to guide the melodic and harmonic structure of new compositions. This flexibility makes it particularly powerful for creators who want to maintain specific musical elements while exploring new arrangements and productions.
Melody Conditioning
You can upload reference audio to guide the melodic and harmonic structure of the generated music. This is particularly useful for reimagining existing melodies in different styles, creating variations of musical themes, and maintaining melodic consistency across different arrangements.
Advanced Controls
MusicGen offers advanced controls for fine-tuning the generated music, including Multi Band Diffusion for improved audio quality, Normalization Strategy for consistent volume levels, Temperature for controlling creativity, and Guidance for determining how closely the model follows your prompt.
Google Lyria 2
Google Lyria 2 is Google's latest advancement in AI-powered music generation, offering creators the ability to generate high-quality instrumental music through intuitive text prompts. Lyria 2 excels at understanding musical concepts, genres, and emotional contexts to produce coherent, professional-sounding compositions. More on this section
Key Features:
High-Quality Instrumental Music
Lyria 2 is optimized for instrumental music generation and works best with descriptive text prompts that specify genre, mood, instrumentation, and style.
Genre Coverag
The model supports classical, jazz, pop, electronic, and orchestral music, along with various regional and fusion styles.
Negative Prompt
You can use the Negative Prompt field to exclude unwanted elements from your music, such as vocals, harsh distortion, or specific instruments.
SFX (ElevenLabs Sound Effects v2)
Design Your Auditory World
For detailed sound design, use Scenario’s text-to-sound effects tool, powered by ElevenLabs Sound Effects v2. This model turns short prompts into polished, loopable sound effects, perfect for things like ambient background sounds. Just describe the sound you need, like “a knock at the door,” or “Campfire crackling” and generate polished, ready-to-use effects in seconds. More on this section
Key Features:
Contextual Sound Generation
The model excels at creating environmental sounds, mechanical effects, organic textures, impact and collision sounds, plus atmospheric and specialized audio effects for comprehensive sound design needs.
Loopable Audio
You can enable the loop toggle to create seamless audio loops for continuous sounds like rain or hums.
Detailed Prompts
You can craft effective sound descriptions by including the sound source, material/surface, environment, and intensity/quality. For more advanced results, you can add acoustic properties, temporal elements, contextual details, and emotional tone.
Lip Sync Animation: Bringing Characters to Life
And finally, lip sync animation, found in the “Video generation” tools. Just open the main Video generation interface, and select from the dedicated Lip Sync models to get started.
You can choose from a wide variety of specialized models, ranging from high-fidelity avatars like Omni Human 1.5 and Kling AI Avatar 2, to specialized tools for stylized motion or fast clips. Each model offers a different look, feel, or level of control to suit your specific project needs.
All lip-sync models on Scenario are covered in a dedicated section of the Knowledge Base, available here: https://help.scenario.com/en/c/lip-sync. This section includes both high-level overviews and in-depth documentation for specific models.
AI lip sync technology allows the synchronization of a character’s or person’s lip movements with an audio track or written text converted into speech. Depending on the model, you can upload an image or video together with audio, or simply provide text to generate both the voice and the synchronized lip movement.
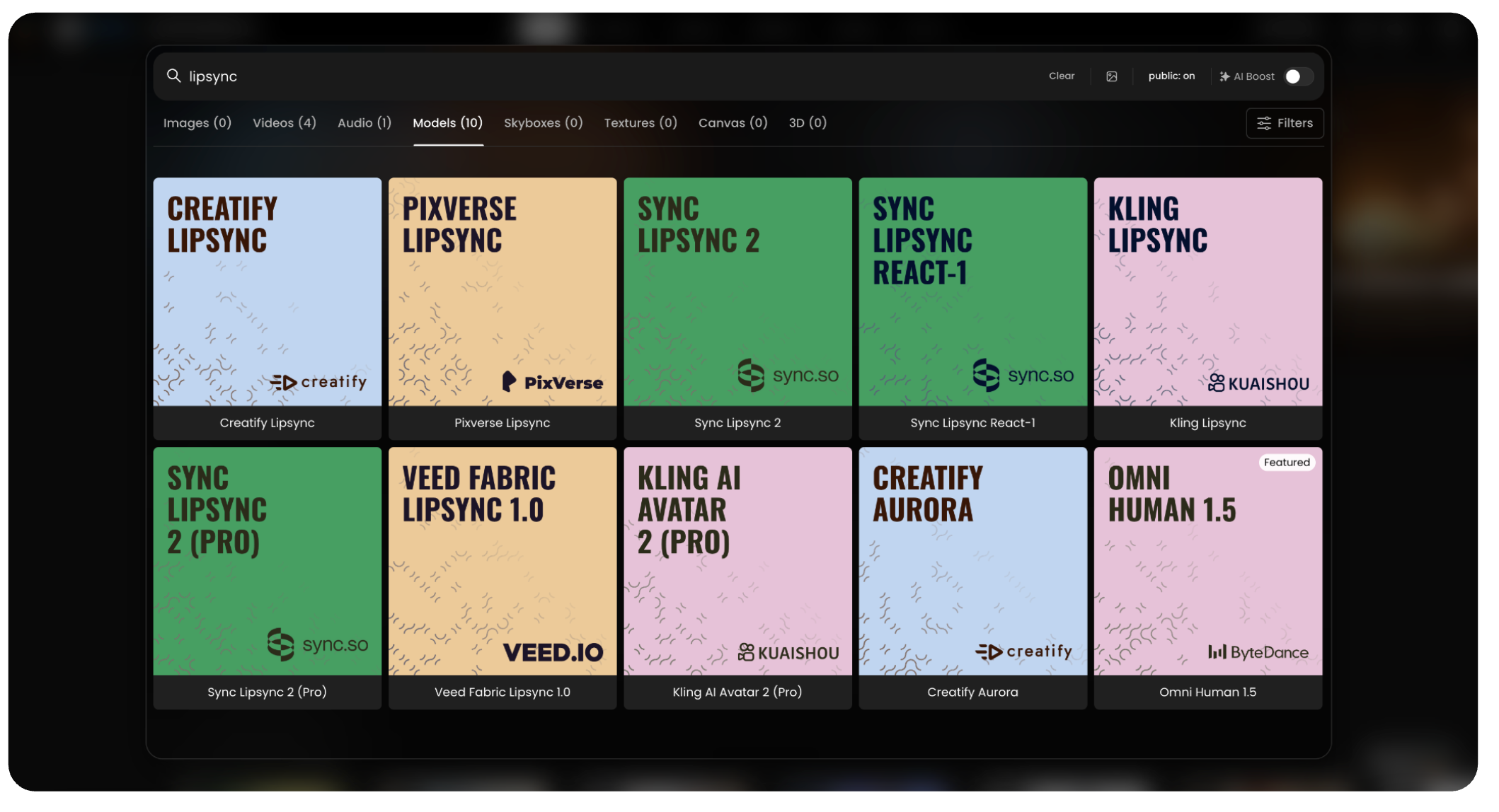
Available Models:
Omni Human 1.5: (ByteDance) Generates digital humans from a single image and audio file, creating high-quality avatars with natural gestures.
Creatify Aurora: A specialized model by Creatify designed for creating dynamic, lifelike character animations.
Sync Lipsync React-1: Tailored for reactive video generation, syncing lip movements perfectly for reaction-style content.
Kling AI Avatar 2 (Pro): The advanced professional version of the Kling avatar model, offering higher fidelity and enhanced control.
Veed Fabric Lipsync 1.0: This model provides seamless lip synchronization integrated with Veed's video fabric technology.
Sync Lipsync 2 (Pro): A professional-grade “zero-shot” model that aligns video with new audio while preserving the original speaking style with high precision.
Pixverse Lipsync: Part of a broader video generation ecosystem, offering lip sync combined with visual effects and cinematic quality.
Creatify Lipsync: A tool for creating looped lip sync animations, with fast generation for short, lightweight videos.
Sync Lipsync 2: The standard “zero-shot” model that aligns any video with new audio, featuring multi-speaker support.
Kling Lipsync: Focused on short, fast lip sync generation from uploaded video and audio or text, with adjustable voice speed and type.
A Complete Solution for Creative Audio Workflows
No matter what you're creating, voiceovers, music, sound effects, or animated dialogue, Scenario’s audio tools are built for speed and flexibility, providing a complete solution for creative audio workflows. From expressive speech and cinematic sound to stylized performance and lip sync animation, everything works together to give you full control from the first prompt to the final frame.
Was this helpful?