
Overview
Marey is a video generation system designed for high-end film and animation production. It is trained on licensed content, ensuring safe and ethical use. The model emphasizes granular control over camera movement, object dynamics, and scene consistency, offering modes such as text-to-video, image-to-video, motion transfer, and pose transfer to support a wide range of creative approaches.
The Marey family includes four main modes:
Text-to-Video (T2V) – generates a new video entirely from a text prompt.
Image-to-Video (I2V) – animates a still image (first frame) guided by a text prompt.
Motion Transfer – applies the camera and object movements from a reference video to a new scene, using a prompt and a first frame, with the option to add a reference image.
Pose Transfer – transfers human gestures and expressions from a reference video to a new character or scene, based on a prompt, and can also incorporate a reference image.
In short: T2V requires only a prompt; I2V needs a prompt plus an initial image; Motion Transfer combines a reference video, first frame, and prompt (with optional reference image); and Pose Transfer uses a reference video and prompt, with an optional reference image or first frame.
Key strengths
Ethical training and commercial safety
Licensed data – Marey is one of the few commercial models trained with a fully licensed dataset, reducing legal risks and ensuring safe use.
Quality and flexibility
Cinematic resolutions – Marey generates videos in 1080p or 1920 × 1080 by default, suitable for professional productions.
Controlled duration – The user chooses 5 or 10 seconds (or longer sequences by concatenating segments), with a seed to control randomness.
Negative prompt and seed – Fields to steer away from undesirable elements and reproduce results.
Narrative and artistic focus
Cinematic properties – Marey understands lens descriptions (e.g., 35 mm, field of view), lighting styles (film noir) and camera motion to generate rich scenes.
Built for cinematography – Marey was designed for filmmakers and that the major differentiator is control.
Models and parameters
1. Text‑to‑Video (T2V)
Description – Generates a completely new video from a detailed text prompt, with no need for an initial image. The model creates complex compositions, camera movements and visual style according to the instructions.
Required input:
1. Prompt – describe scene, camera movement, environment, characters and action with at least 50 words.Additional settings:
Dimension – choose video size (default 1920 × 1080).
Duration – 5 or 10 seconds.
Negative prompt – list elements to avoid.
Seed – controls randomness (default 9; use ‑1 for a random seed).Quick start – Create a detailed prompt, adjust dimensions and duration, set a negative prompt and seed, click Run and preview. Adjust the prompt if needed and re‑generate.
2. Image‑to‑Video (I2V)
Description – Transforms an image or keyframe into a video, adding cinematic motion. Enables cameras that orbit, dive or slide around the scene.
Required inputs:
1. Prompt – describe the scene, camera motion and technical details (≥ 50 words).
2. Image URL – image that will serve as the first frame.Additional settings – similar to T2V: dimension, duration (5 or 10 seconds), negative prompt and seed.
3. Motion Transfer
Description – Uses a reference video to control the motion of the new generation. The camera and object movements from the base video are transferred to a new video, combined with a prompt and optionally an initial image.
Required inputs:
1. Prompt – detailed description of the new scene and style (≥ 50 words).
2. Reference video URL – video containing the motion to be reapplied.Optional inputs:
* Reference image URL – defines the first frame, applying the motion from the video to this image.Additional settings – negative prompt and seed.
4. Pose Transfer
Description – Transfers human poses and expressions from a reference video to a new character or scene. Ideal for reproducing choreography or performances. It works only with human movements; animal motion is not preserved.
Required inputs:
1. Prompt – detailed description of scene, camera, environment and style (≥ 50 words).
2. Reference video URL – video with the human performance to be transferred.Optional inputs:
Initial image URL – defines the first frame for applying the performance.
Reference image URL – another image to which the performance will be applied.Additional settings – negative prompt and seed.
Prompting guidelines (five‑step formula)
To achieve cinematic results, Moonvalley recommends a five‑step formula:
Camera movement or angle – use dynamic expressions like plunge, dive, aerial sweep, first‑person view or high/low angles.
Scale – compare objects to large reference points (buildings, mountains) to convey grandeur.
Geological language – describe forms as if they were living landscapes, using terms like undulating, surging, formations.
Layered structure – separate background, midground and foreground, describing elements in each layer.
Technical details – finish with lens, sensor, lighting or effects specifications, such as 35 mm, motion blur, noir lighting.
Marey prompts should have at least 50 words, follow the structure [Camera movement] + [Scale/Perspective] + [Core visual] + [Environmental details] + [Technical specs], and should not include negative terms (these belong in the negative prompt field).
Practical Examples
Example 1 – Man Surfing (T2V)
This example demonstrates a simple Text-to-Video generation, starting from a written prompt only. The model interprets the scene, motion, and atmosphere entirely from text.
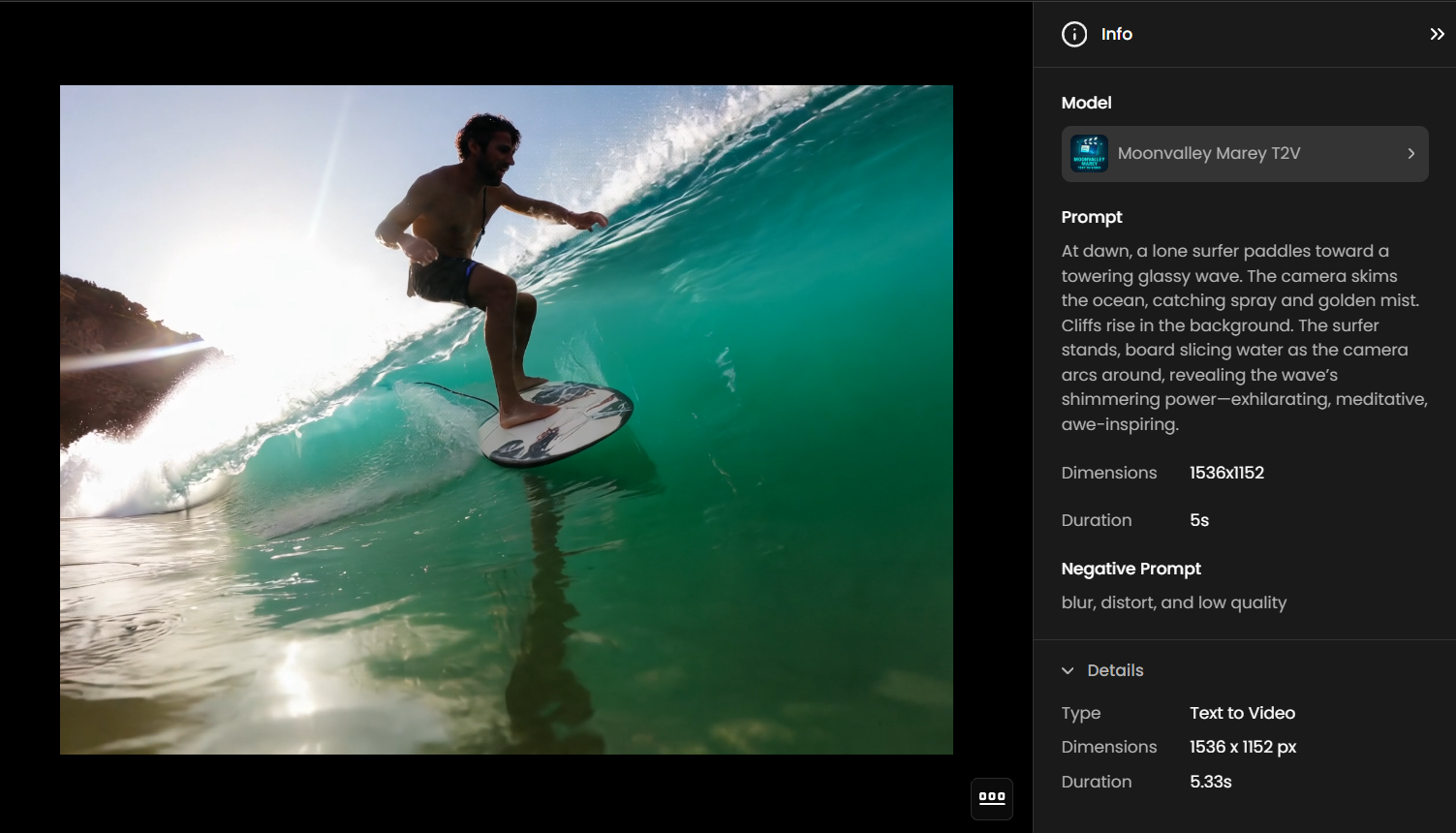
Prompt:
At dawn, a lone surfer paddles toward a towering glassy wave. The camera skims the ocean, catching spray and golden mist. Cliffs rise in the background. The surfer stands, board slicing water as the camera arcs around, revealing the wave’s shimmering power—exhilarating, meditative, awe-inspiring.
Settings:
Dimensions: 1536×1152
Duration: 5 s
Result:
A short cinematic sequence showing a surfer riding a massive wave at sunrise, with camera motion emphasizing scale, light, and atmosphere.
Example 2 – Desert Biker (I2V)
Here, Image-to-Video (I2V) takes a single still frame and animates it into a dynamic sequence. This example also shows that slightly longer prompts can be effective, giving the model more cinematic detail to work with while preserving the original art style.
Prompt:
A lone biker in a red armored suit, helmet visor blazing under the desert sun, rides a bright orange motorcycle across a vast cartoon desert framed by towering sandstone cliffs. The camera follows in a low, side-angle tracking shot as the bike tears forward, tires spitting dust and pebbles into swirling clouds that trail far behind. Heat haze shimmers at the horizon, while elongated shadows cut across the arid ground. Scarves lash violently in the slipstream, echoing the merciless desert wind. Foreground rocks blur in motion, heightening the sensation of breakneck speed.
Settings:
Dimensions: 1920×1080
Duration: 5 s
Result:
A high-energy sequence of a biker racing through a blazing desert canyon, with dynamic tracking shots, dust trails, and heat-haze effects that enhance the adrenaline-fueled atmosphere.
Example 3 – Forest Inferno (Motion Transfer)
This example shows Motion Transfer, where the camera movement from a reference video is applied to a new generated scene. It keeps the motion path but reimagines the content with fire and smoke.
Prompt:
A smoky aerial view of a burning forest ablaze with vivid orange flames, rivers of fire spreading through the treetops. Thick dark smoke billows upward, drifting across the sky, while glowing embers scatter like sparks. The camera glides overhead, revealing the vast scale of the wildfire consuming the landscape.
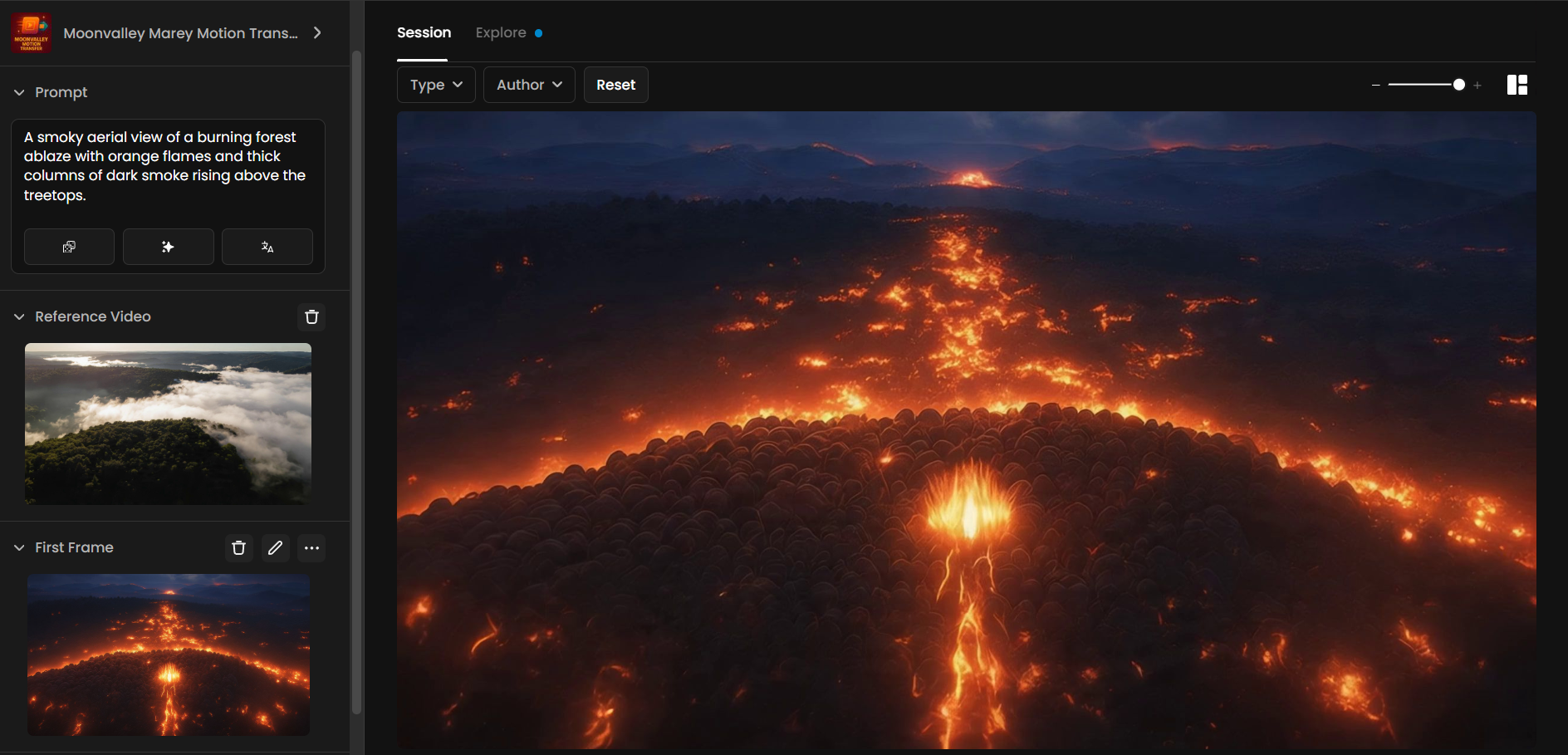
Settings:
Dimensions: 1920×1080
Duration: 5 s
Result:
A dramatic motion-transfer sequence where reference camera movement applies to a fiery forest scene, blending smoke, flames, and glowing lava-like textures into a cinematic aerial shot of destruction.
Example 4 – Young Wizard (Pose Transfer)
Pose Transfer uses the body position and gestures from a reference actor to drive an animated character. The result preserves pose accuracy while transforming appearance and environment.
Prompt:
A slow tracking shot reveals a young wizard child with messy curly hair, wearing a flowing red robe, standing bravely on a crumbling dungeon bridge above a dark abyss. The child raises a glowing wooden wand, sparks of magic flickering as light reflects on jagged stone walls and swaying chains. Shadows shift ominously in the background, water drips onto cracked stone tiles, and dust floats in the torch-lit air.
Settings:
Dimensions: 1920×1080
Duration: 8 s
Result:
A cinematic pose transfer shot where the child actor’s stance drives the animated wizard’s movement, blending glowing effects, shifting shadows, and dramatic low-angle perspective into a perilous dungeon scene.
Conclusion
Moonvalley Marey models represent a step forward in AI video generation, combining ethical training with advanced cinematic controls. By offering Text‑to‑Video, Image‑to‑Video, Motion Transfer and Pose Transfer modes, the platform provides versatility for different stages of audiovisual creation—from pre‑visualizing scripts to complex animations.
The key to good results lies in the quality of the prompt: describe camera movement, scale, visual elements and technical details precisely, using the five‑step formula and keeping 50 words or more. With these practices and the granular control offered by Marey, creators can generate high‑fidelity videos that are safe for commercial use and aligned with the demands of film professionals.
Was this helpful?