Introduction to Flux Kontext LoRAs
Flux Kontext Dev LoRAs offer a powerful new paradigm for AI image editing, together with sophisticated editing models like Gemini 2.5, Seedream Edit, and Qwen Edit. Training a Flux Kontext Dev LoRA essentially means creating your own personalized editing model that combines granular control with remarkable consistency and ease of use.
This approach enables sophisticated and very subtle edits such as changing lighting, applying artistic styles, or editing proportions, while preserving the core elements of the original image.
This guide provides a comprehensive overview of training Flux Kontext Dev LoRAs on Scenario, exploring the fundamental concepts, dataset preparation, and best practices to help you master this powerful technique.
The Core Concept: Training Pairs
The foundation of Flux Kontext LoRA training is the training pair, which consists of three essential components: an input image, an output image, and most importantly, an instructional caption that describe the transformation. This differs fundamentally from traditional LoRA training, which primarily focuses on associating one training image with one caption describing it.
FLUX.1 Kontext is a model that combines text-to-image generation with advanced image editing capabilities. This dual functionality makes Kontext exceptionally powerful—it understands the content of an existing image and modifies it based on both the visual example and the textual instruction, rather than generating an entirely new image.
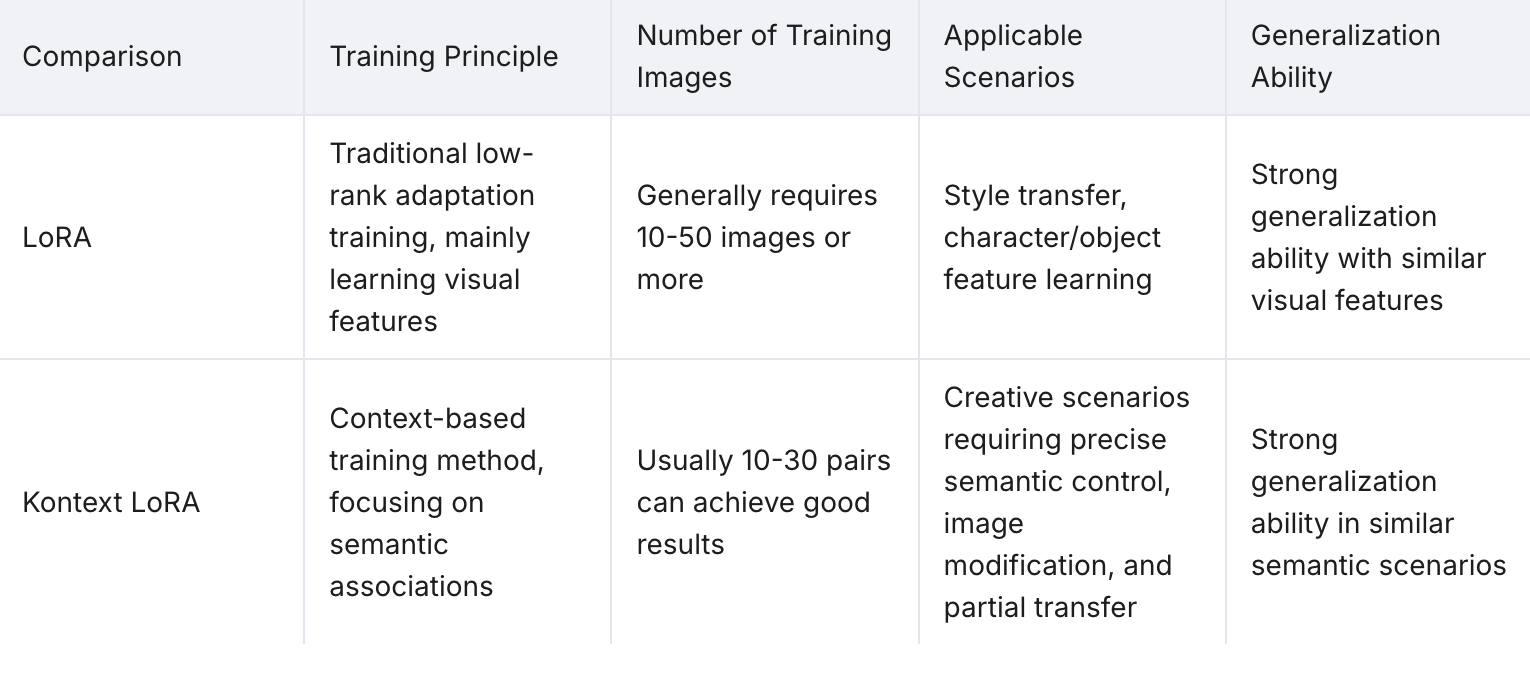
The Three Components of a Training Pair
Each training pair in Flux Kontext LoRA training consists of:
Before/Input Image: The “original“ image that serves as the starting point
After/Output Image: The transformed version of the original image showing the desired result
Caption/Instruction: A text description that explains what transformation should occur
The caption is crucial because it teaches the model not just what the transformation looks like visually, but also how to interpret and execute similar transformations when given text instructions during inference.

How Captions Work in Training Pairs
Unlike traditional LoRA training where captions simply describe what's in an image, Flux Kontext LoRA captions are instructional. They tell the model what action to perform. The caption format typically follows this pattern:
> "Transform this [input description] into [desired output] using [trigger word]"
For example, if you're training a Flux Kontext LoRA to change images to golden hour lighting, your caption might be: "relight this image as golden hour". More generally, the key elements are:
Action verb ("add", "transform", "convert", "apply", "relight" & more)
Transformation description ("anime style", "winter scene", "cinematic color grading", "golden hour lighting")
Trigger word (optional - a unique identifier like "GOLDENHOUR" or "MOVIECOLOR")
Optional: Use Trigger Words
Trigger words are optional in Flux Kontext LoRA training, but they offer additional control and specificity. When used, a trigger word becomes a unique identifier associated with your specific transformation. Similar to Flux Dev LoRA training, you can use a trigger word to teach the AI to associate that word with your transformation. Ensure that the trigger word is not a common English word—artificial or compound words work best.
Training with Trigger Words:
Provides precise control over when the LoRA activates
Useful when you want to apply the transformation selectively
Allows for more complex prompt combinations
Examples:
PIXARSTYLE,VINTAGEPHOTO,OILPAINTING,CYBERPUNK2077
Training without Trigger Words:
The LoRA learns to apply the transformation based on natural language descriptions
More intuitive for users who don't want to remember specific activation words
The model responds to general transformation requests like "make this anime style" or "add cinematic lighting"
Simpler workflow for straightforward transformations
Caption Consistency Across Training Pairs
All captions in your training dataset should ideally follow a consistent format, whether you choose to use trigger words or not. This consistency helps the model understand that all these transformations belong to the same learned behavior.
With Trigger Words:
Every caption should use the same trigger word: "make this image into [trigger_word] style"
Consistent activation phrase across all training pairs
Without Trigger Words:
Use consistent natural language descriptions: "convert this to anime style"
Focus on clear, descriptive transformation language
Maintain the same action verbs and style descriptions throughout
What Makes a Good Training Pair?
A successful Flux Kontext LoRA depends on high-quality, consistent training pairs. The goal is to provide clear, unambiguous examples of the transformation you want the model to learn.
Clear Transformation: The difference between the “before” and “after” images should be distinct and focused. Whether you're changing the time of day, applying a color grade, or altering a character's expression, the transformation should be the primary variable.
Consistency is Key: The transformations across all your training pairs should be consistent. If you're training a LoRA to apply a vintage film look, all your output images should have a similar aesthetic.
High-Quality Images: Use high-resolution images (at least 1024x1024) to ensure the model can learn fine details
Examples of Effective Training Pairs
These are some examples of possibly trianing pairs from simple to elaborate
Instruction: “Create 3D game asset, isometric view version of this [person/object].”
Such a Kontext LoRA will take a realistic image and transform it into a stylized 3D character or object, suitable for use in games or animation pipelines.

Instruction: “Add broccoli hair to this person.”
This Kontext LoRA is trained to apply a highly specific transformation — turning any person’s hair into a whimsical “broccoli hair” version. It demonstrates how LoRAs can learn niche, humorous, or exaggerated stylistic conversions.

Instruction: “A Glittering Portrait of this person.”
This LoRA adds cinematic lighting, reflective skin highlights, and stylized color grading, producing a polished “red-carpet” or “editorial photography” effect across portraits.

Instruction: “Transform into geometric cubist painting style.”
This LoRA reinterprets the input in a Cubism-inspired visual language, breaking forms into angular shapes and bold color planes. It teaches the model to generalize an abstract art transformation across different subjects — portraits, objects, or environments.

Step-by-Step Guide
Step 1: Access Flux Kontext Training on Scenario
Navigate to Create → Train, then click Start Training and choose Kontext as the base model. Click Next.
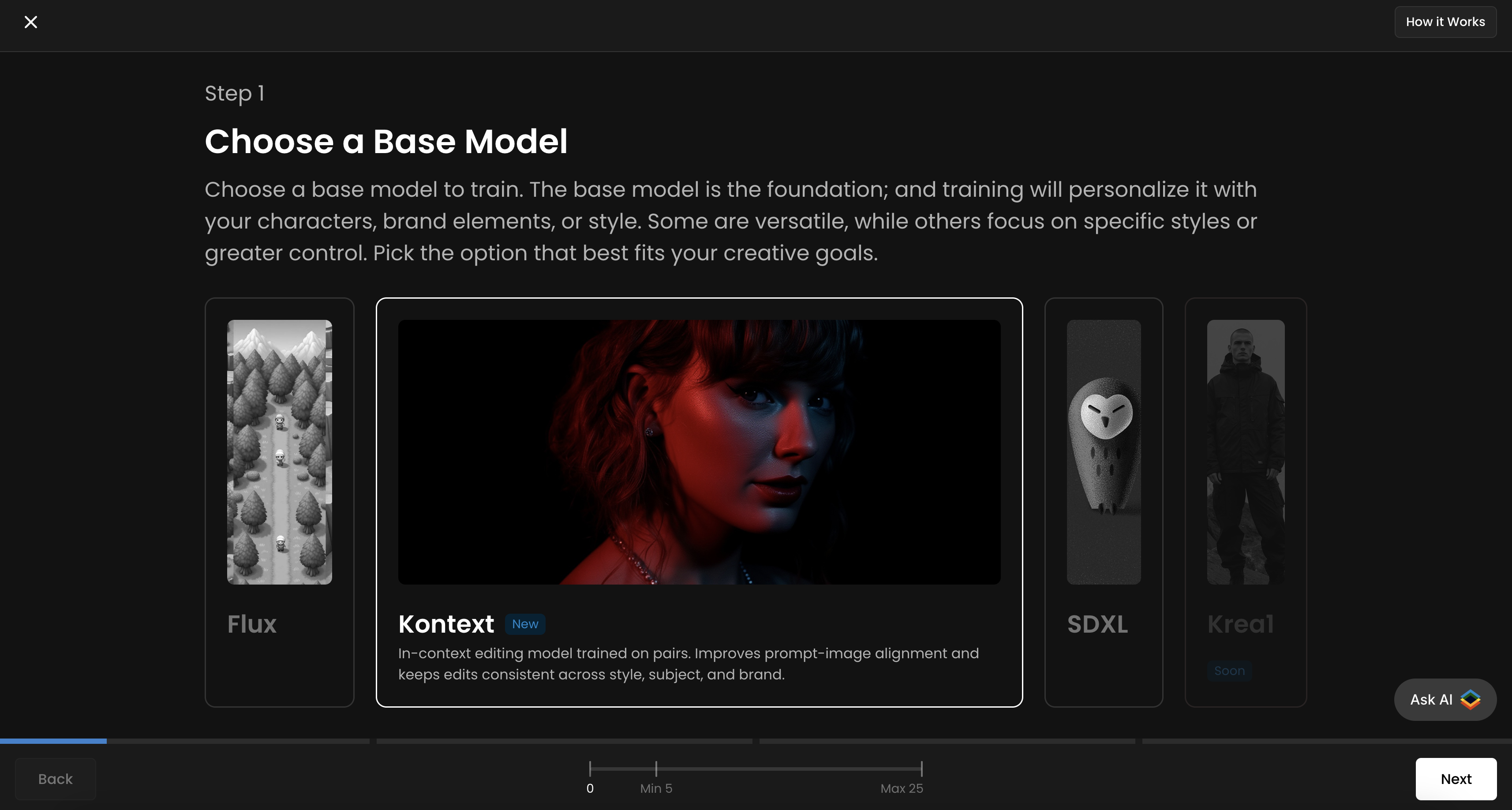
Step 2: Curate and Upload Your Training Dataset
Before/Input images: Your original, unedited "before" images
After/Output images: The transformed "post-edition" images showing your desired result
It’s good to aim for 10–20 high-quality pairs that clearly illustrate the transformation you want the model to learn. You can upload, drag and drop, paste from your clipboard, or select images from your Scenario library.
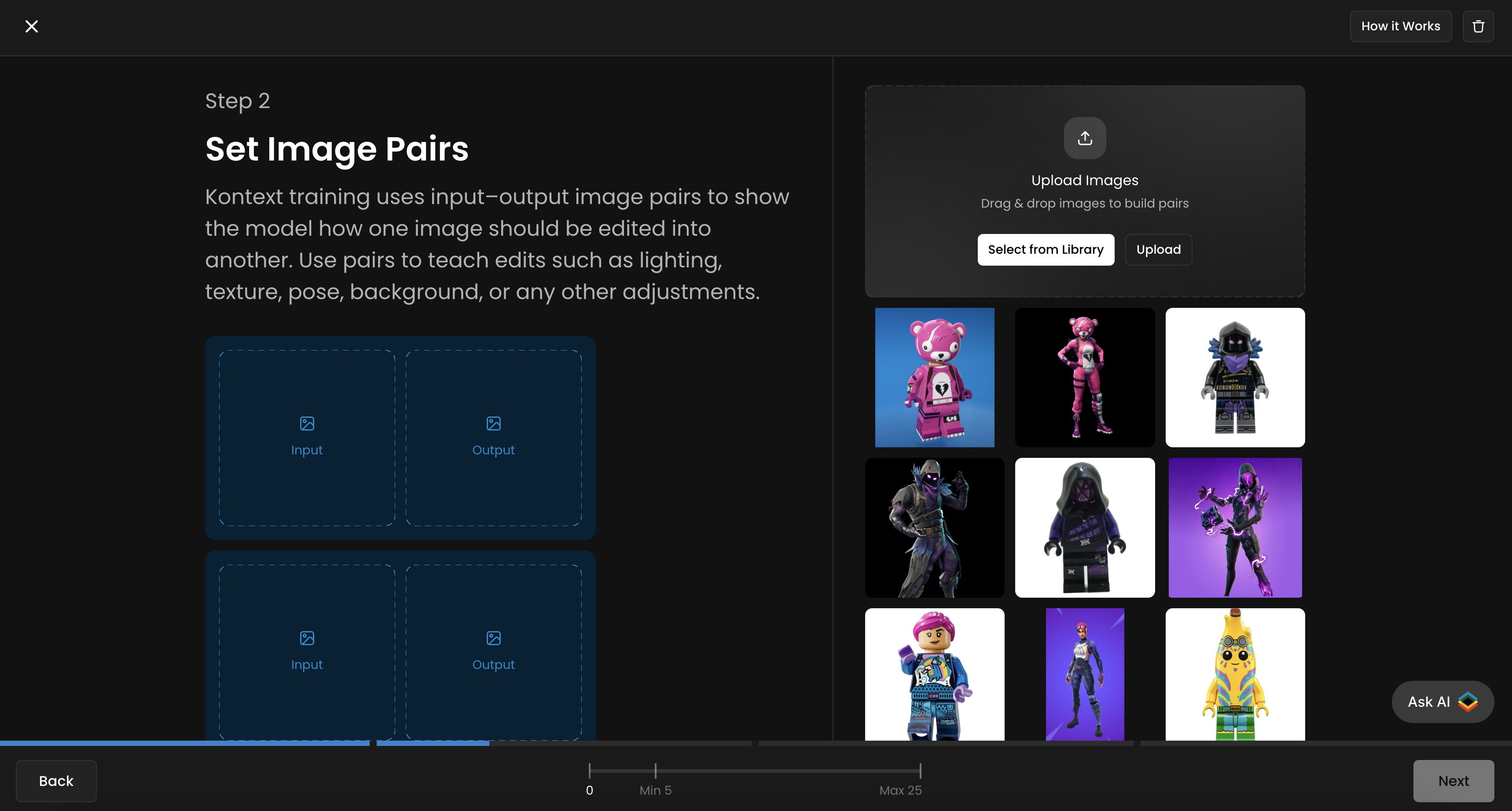
Step 3: Caption Your Pairs
Describe the transformation action using clear, imperative language
Be concise but descriptive about the desired outcome
Maintain consistency across training pairs (whether using trigger words or not)
You can either keep the same caption/instruction for all pairs, or tailor each one to better suit its specific pair.
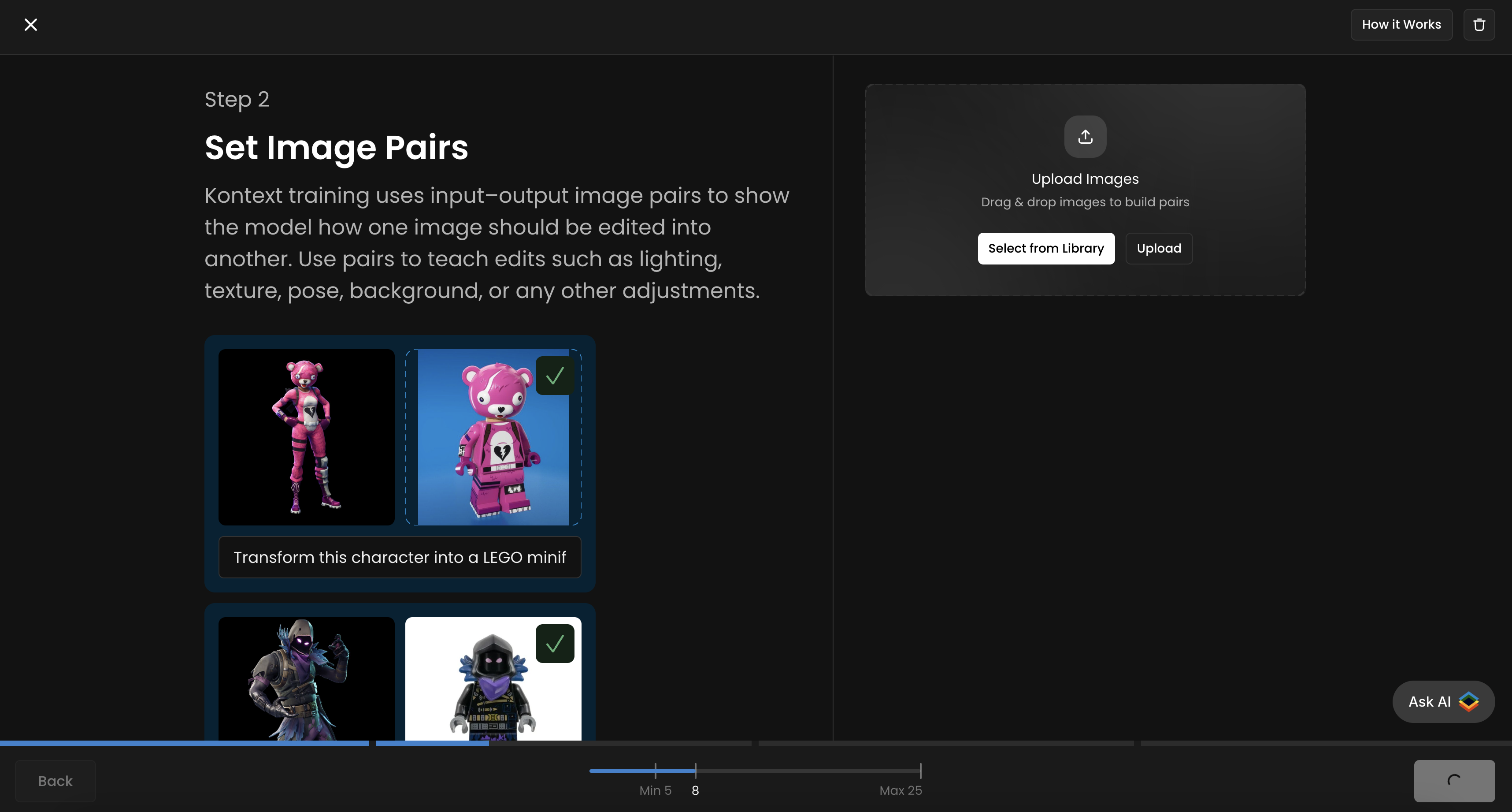
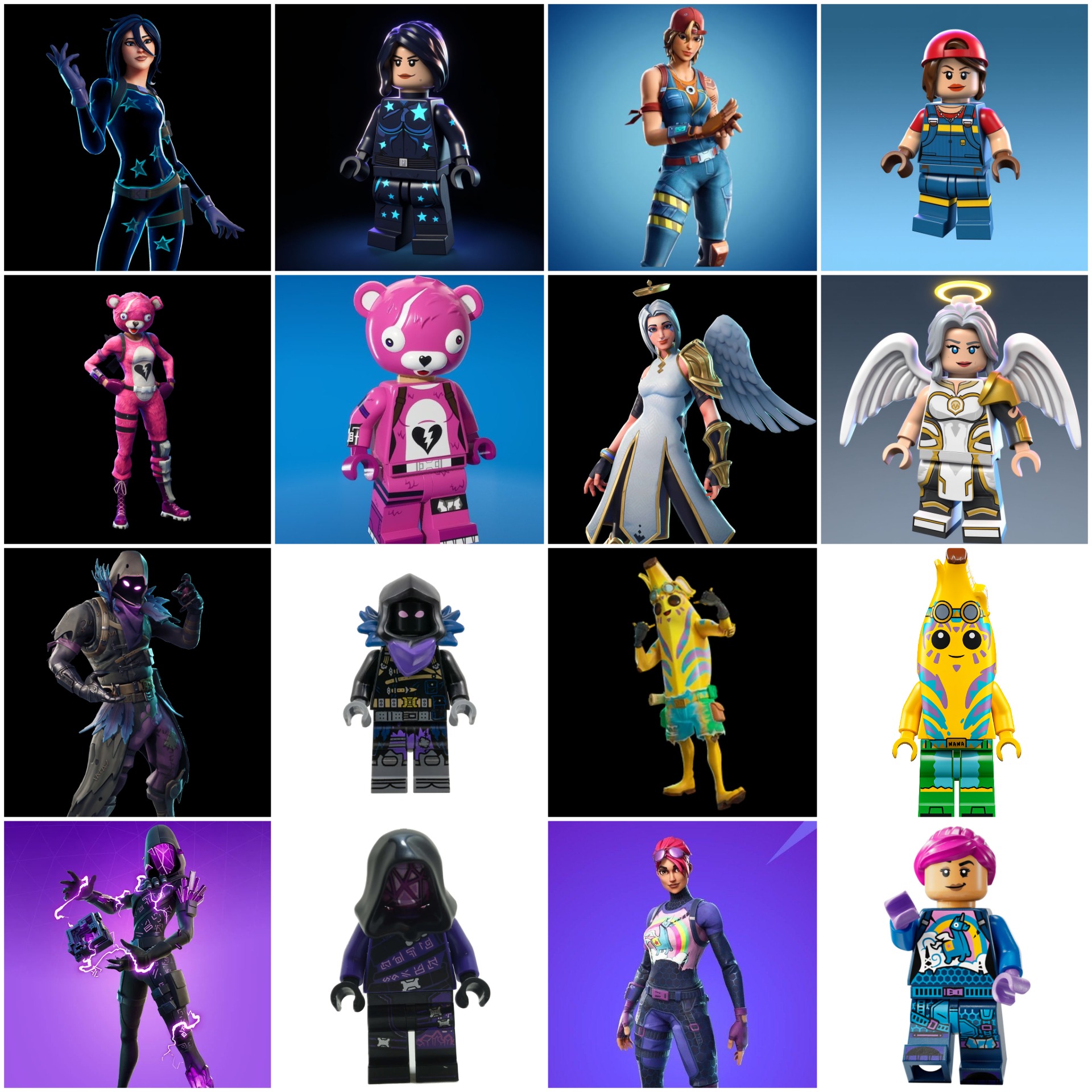
This Flux Kontext LoRA is designed to transform any Fortnite character into a LEGO minifigure. Each training pair includes a before image (Fortnite character) and an after image (LEGO version). The caption/instruction used is: “Transform this character into a LEGO minifigurine” (same for all pairs). The training set consists of 8 pairs, below:
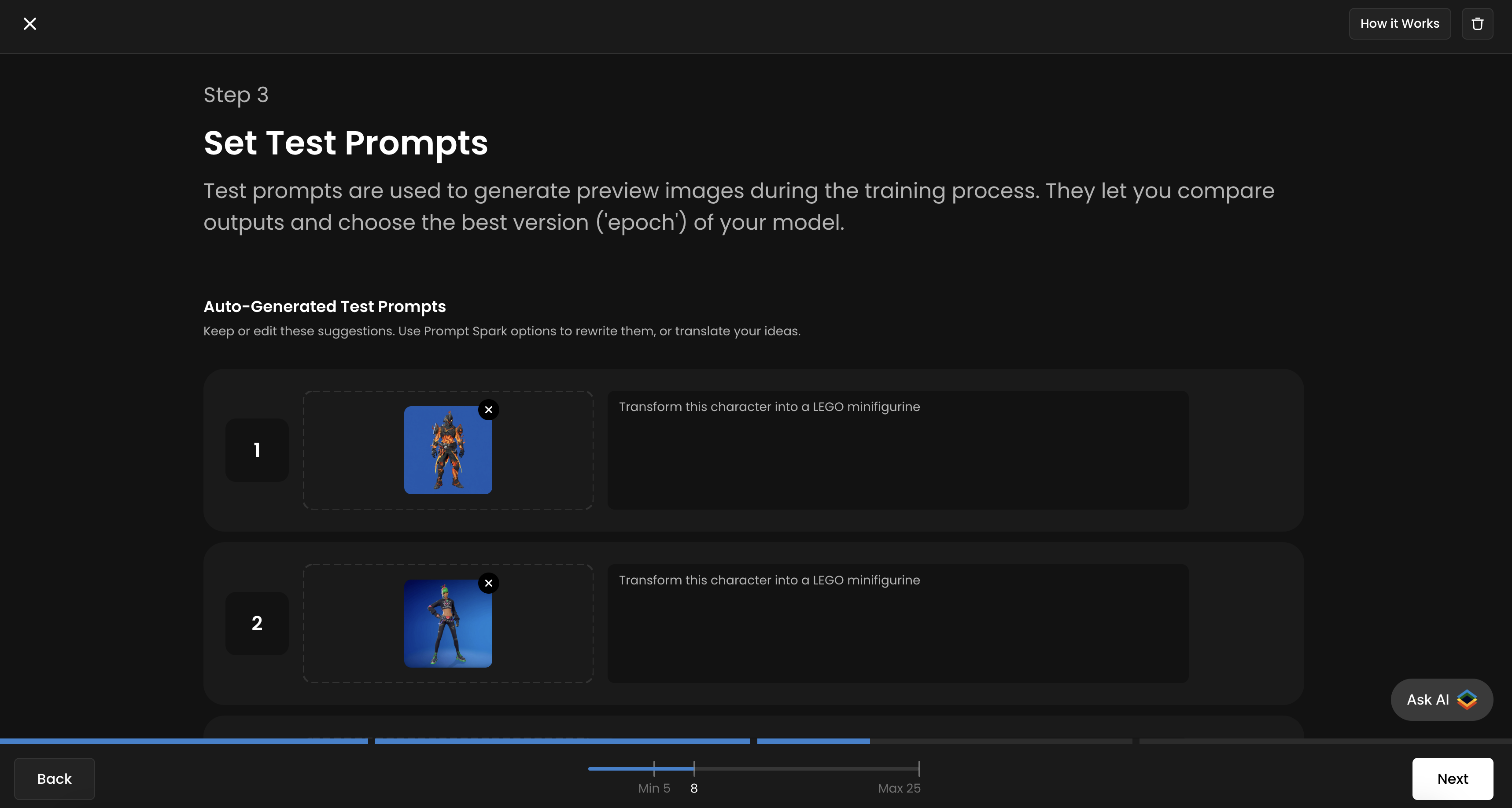
Step 3: Set Test Prompts
Scenario allows you to upload up to four test prompts/test pairs to track your training progress and evaluate the quality of each epoch. It’s recommended to use all four slots for more accurate monitoring throughout the training process. You’ll then be able to compare different epochs side by side and select the best-performing one.
For each slot, upload a new “input/before” image that is not part of your training dataset, and provide the corresponding prompt or instruction next to it. You will see the corresponding “output/after” image generated for each epoch.
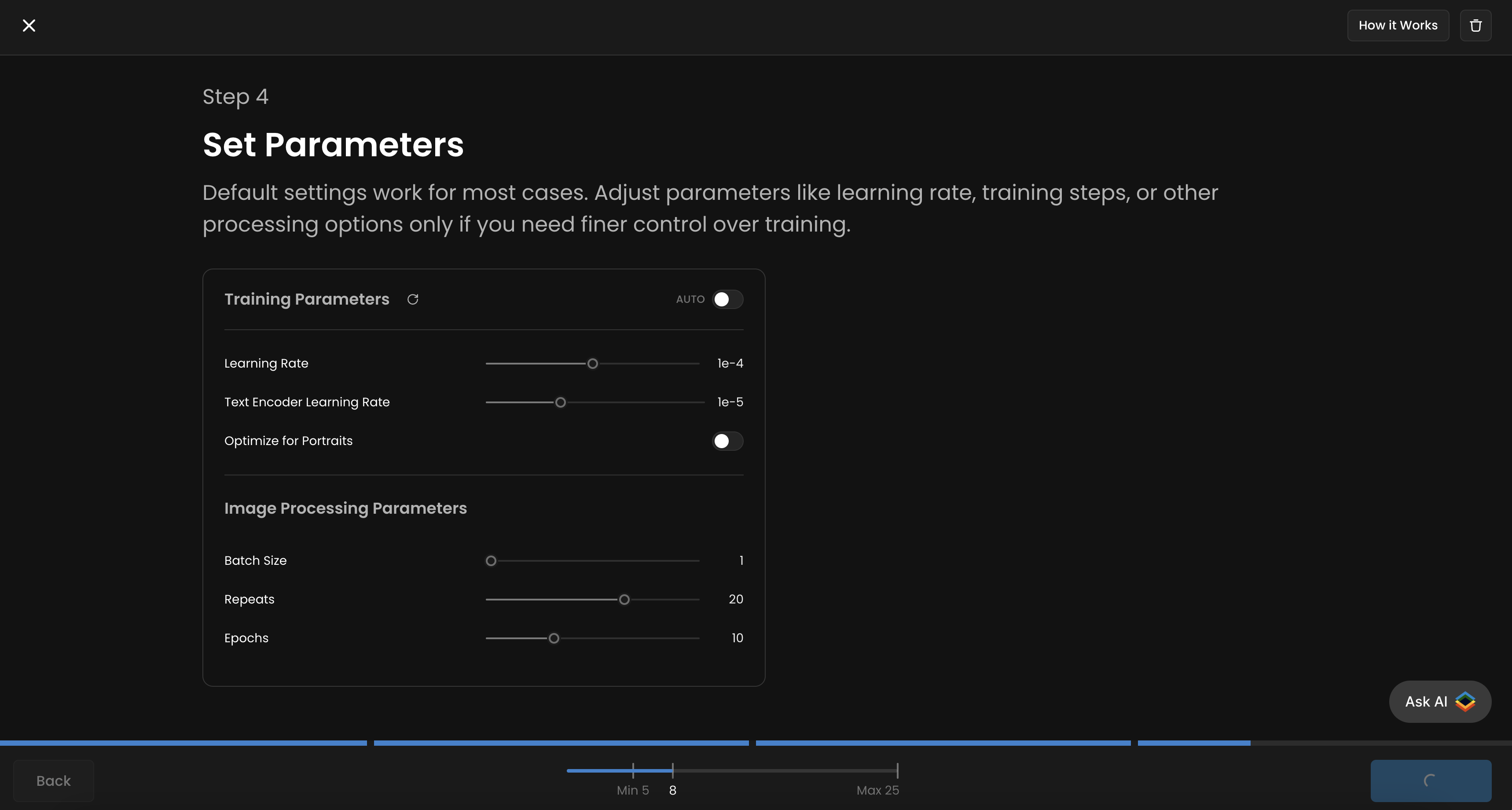
Step 4: Configure Training Parameters
Once your dataset is prepared and captioned, you'll configure the training parameters through Scenario's user-friendly interface. The platform provides an intuitive "Set Parameters" section where you can adjust various settings to optimize your training.
Default settings work for most cases. Adjust parameters like learning rate, training steps, or other processing options only if you need finer control over training. The interface includes two main parameter categories:
(i) Training Parameters:
Learning Rate (default: 1e-4) - Controls how quickly the model learns
Text Encoder Learning Rate (default: 1e-5) - Finetunes text understanding
(ii) Image Processing Parameters:
Batch Size (default: 1) - Number of images processed simultaneously
Repeats (default: 20) - How many times each image is used during training
Epochs (default: 10) - Number of complete passes through your dataset
Step 5: Initiate and Monitor Training
With your dataset and configuration file in place, you can begin the training process. The training process can take 30-45 min to a few hours, depending on the size of your dataset and you training parameters.
During training, the model will periodically generate sample images based on your test prompts. These samples allow you to monitor the model's progress in Epochs, and see how well it's learning the desired transformation. Once the training is complete, the model will be ready to use on Scenario and you'll be able to download have the .safetensors file.
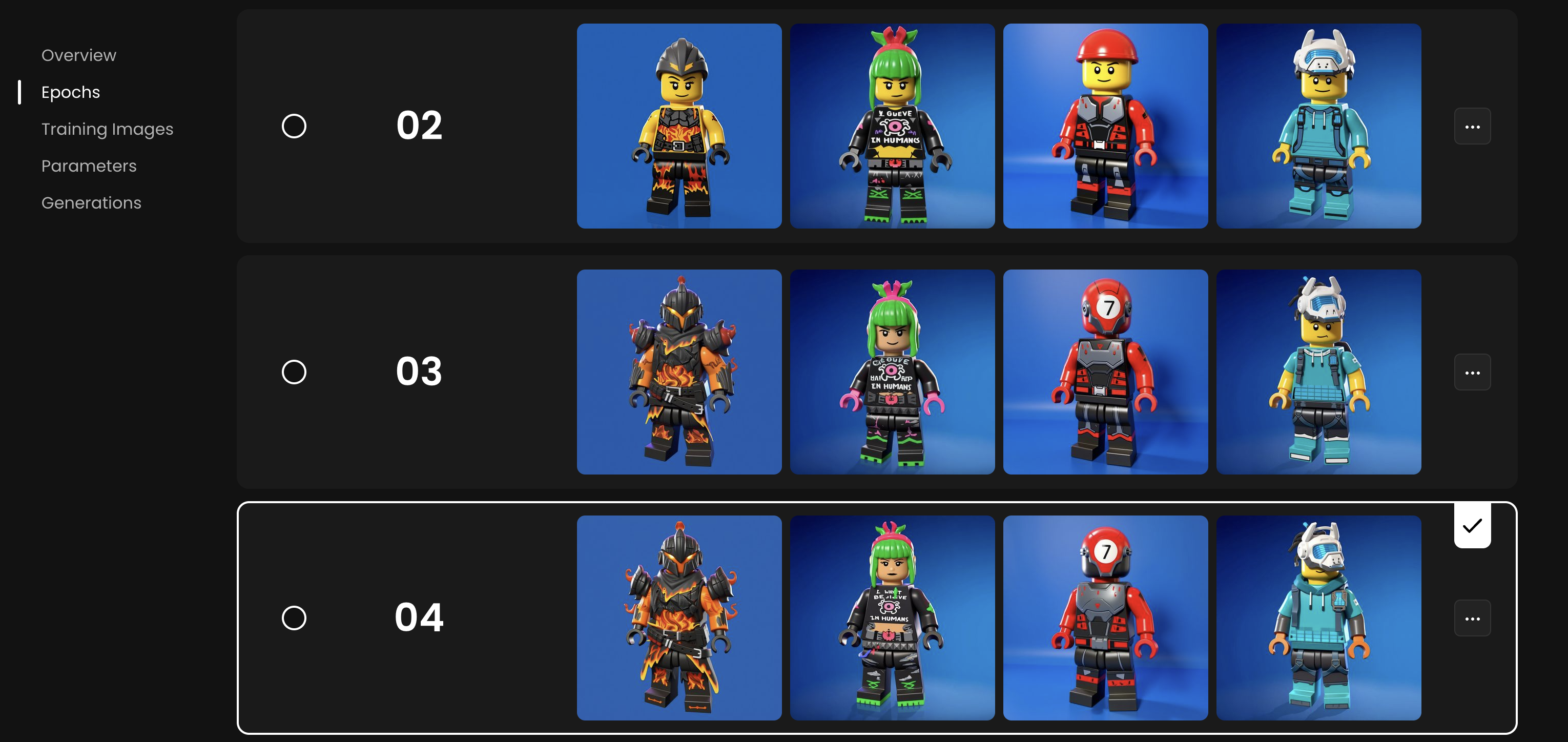
As training progresses, each epoch produces a more refined LoRA, resulting in increasingly accurate and consistent transformations.
Step 6: Access your new Kontext LoRA
After your Kontext LoRA has finished training, you have the following options:
Evaluate the epochs
Start by reviewing the generated epochs. You can select two epochs and click “Compare” to view their outputs side by side. While the last epoch is often kept by default, you may prefer an earlier one if you want a slightly less trained but more flexible model. To set a specific epoch as the default, open the three-dot menu on the right and choose it from the list.
Use the trained model
Click “Use this model” to open the Edit with Prompt interface. The base editing model will automatically be set to Flux Kontext (top left), and you’ll see your LoRA loaded beneath it with a slider to adjust its influence (default = 1, range = 0–2).
Finally, upload a new image to edit and enter a prompt or instruction that matches the captions you used during training.
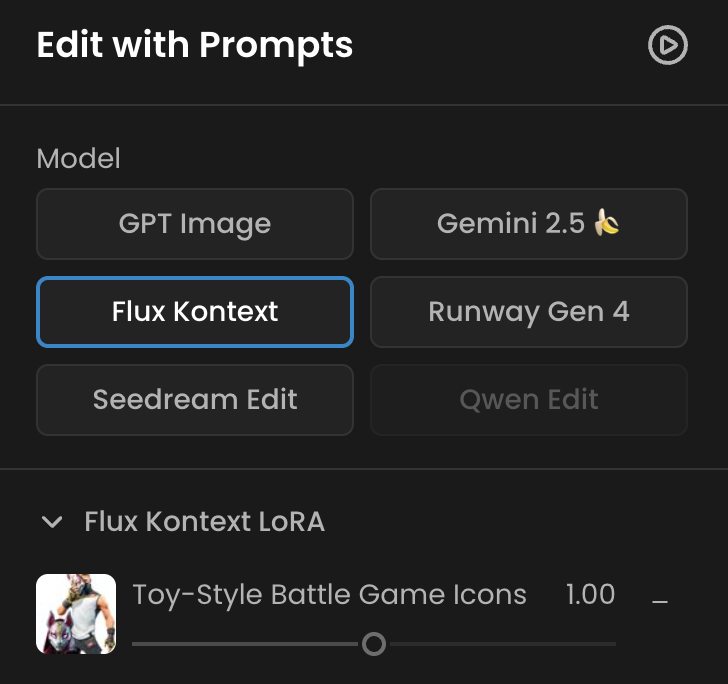
You can also simply head over to https://app.scenario.com/edit-with-prompts, select Flux Kontext as the editing model, and load your LoRA in the top-left menu.
Best Practices and Considerations
Dataset Size
While there's no absolute number, most models will perform great with 10-20 high-quality image pairs. A smaller, well-curated dataset is often more effective than a large, inconsistent one.
Experimentation
Don't be afraid to experiment with different captions, trigger words, pair components or even training steps/epochs or learning rate. The ideal settings will vary depending on your specific use case.
Conclusion
Flux Kontext Dev LoRAs offer a powerful new paradigm for AI image editing. By leveraging the concept of training pairs, you can teach a model to perform specific, complex transformations with a high degree of consistency and control.
While the process requires more preparation than traditional LoRA training, the results are well worth the effort. With a carefully curated dataset and a methodical approach, you can create custom LoRAs that will elevate your creative workflow to new heights.
The combination of visual examples and instructional captions makes Flux Kontext LoRAs uniquely powerful for precise image editing tasks. Whether you're a digital artist, photographer, or content creator, mastering this technique opens up new possibilities for consistent, high-quality image transformations.
References
[1] Black Forest Labs. (n.d.). Introduction. BFL Documentation. Retrieved from https://docs.bfl.ai/kontext/kontext_overview
[2] Hanspal, A. (2025, July 12). Training a Flux Kontext LoRA: A Step-by-Step Guide. Medium. Retrieved from https://medium.com/@amanhanspal05/training-a-flux-kontext-lora-a-step-by-step-guide-6c6ab8ab27b9
[3] Alam, S. (2025, July 2). Noobs guide to Flux Kontext LoRA training. Robotics and Generative AI. Retrieved from https://blog.thefluxtrain.com/noobs-guide-to-flux-kontext-lora-training-7ea8a106d9c2
[4] Stable Diffusion Tutorials. (2025, August 25). Flux Kontext LoRA Training on Windows/Linux Machine. Retrieved from https://www.stablediffusiontutorials.com/2025/08/train-flux-kontext-lora.html
Was this helpful?