
This article was originally posted by shridharathi on the Replicate blog on October 16, 2025 and adapted for clarity. It explains clearly how Veo 3.1 expands on previous Veo 3 versions with more precise control over reference-based generation and scene transitions
In December 25, Google came out with Veo 3.1 which offers a few new shiny tools with video generation, including character reference images and first/last frame input. We made a quick prompting guide to show you the capabilities of this model.
Veo 3.1 (for Pro plans and above): link
Veo 3.1 Fast (for Pro plans and above): link
Veo 3.1 Extend Video (for Pro plans and above): link
As always with the Google video models, there is a general guide you should follow to ensure your outputs are as strong as they can be.
Shot composition: Specify the framing and number of subjects in the shot (e.g., “single shot,” “two shot,” “over-the-shoulder shot”).
Focus and lens effects: Use terms like “shallow focus,” “deep focus,” “soft focus,” “macro lens,” and “wide-angle lens” to achieve specific visual effects.
Overall style and subject: Guide creative direction by specifying styles like “sci-fi,” “romantic comedy,” “action movie,” or “animation.”
Camera positioning and movement: Control the camera’s location and movement using terms like “eye level,” “high angle,” “worm’s eye,” “dolly shot,” “zoom shot,” “pan shot,” and “tracking shot.”
Now that you have a sense of prompting Veo 3.1 generally, let’s dive into these new features.
Reference to Video
The most exciting new feature in Veo 3.1 is reference to video generation. This capability allows you to combine up to three reference images into a single coherent video scene, guided by your text prompt.
Reference to video takes up to three input images and uses your text prompt to guide how these elements should be combined.
Examples
Check out how we used these images of a woman and a bottle of shampoo to make a UGC-style video. Veo 3.1 is able to preserve both the character and the bottle while generating a fluid and realistic review video.

One of the most powerful aspects of reference to video is character consistency. You can take a character reference and place them in completely different scenarios while maintaining their appearance and identity. This opens up incredible storytelling possibilities - imagine taking your brand mascot or main character and seamlessly placing them in various environments, ones you could have never imagined them to be a part of.
Example with this reference:

Being transformed with this prompt “> this character is walking home in the rain” (Original post by FOFR)
This feature provides unprecedented controllability over your video scenes, making it perfect for creating complex narratives with specific visual elements.
First and Last Frame to Video
Another powerful new feature is first and last frame to video generation. This extends the concept of image-to-video by allowing you to specify both the starting and ending frames of your video.
Instead of just providing a starting image like traditional image-to-video, you provide both a first frame and a last frame. The model then interpolates between these two points based on your text prompt guidance.
Examples
Here’s a cool example where we used first and last frame to create a morphing transformation from a lamb to a tiger:

First/last frame interpolation creates compelling transformation sequences that would be difficult to achieve with traditional video generation methods. Take a look at this magical room transformation.
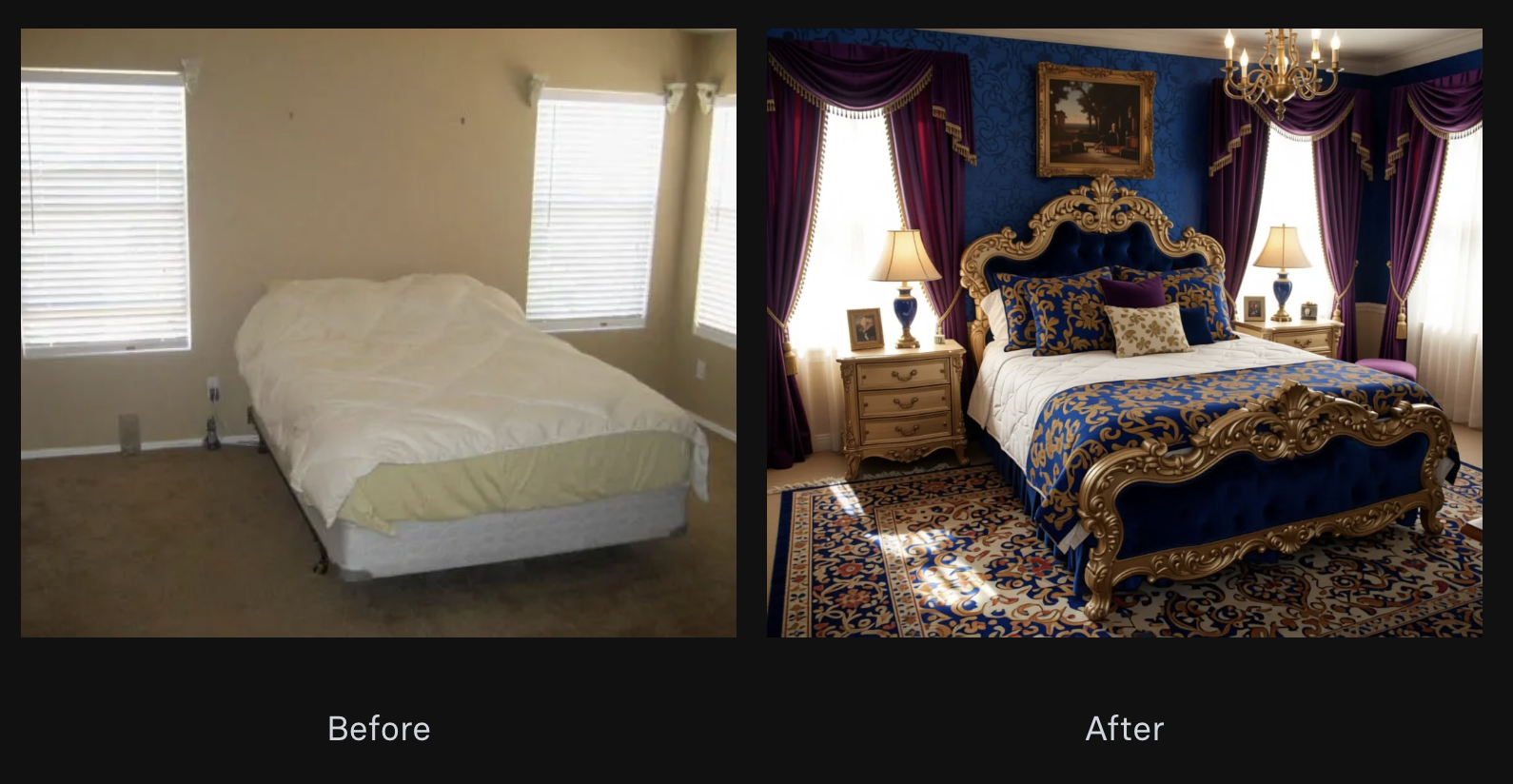
Stagers and interior designers, are you feeling inspired?
This feature is particularly useful for creating videos with specific start and end points, giving you precise control over the narrative arc.
Enhanced Image to Video
The classic image-to-video functionality has been improved in Veo 3.1, offering better quality and more responsive prompt following.
How It Works
Provide a single starting image and a text prompt describing the desired motion or action. The model generates video content that begins with your image and follows your prompt instructions. We’ve also noticed that there is knowledge baked into the video model as it is able to reason from inputted images.
Here’s a cool example where we took an input image of our HQ on maps and asked it to show what goes on in the location:
Veo 3.1’s enhanced image-to-video feature includes intelligent logic that creates fluid transitions. The model understands the content of your input image and generates motion that feels natural and purposeful.
There was no need to prompt for a specific transition here — Veo 3.1 was able to pick up on the information in the image and transition to an appropriate video sequence that makes contextual sense.
Extend Video
Veo 3.1 Extend Video is a continuation model that lengthens existing Veo clips by adding 7 to 8 seconds of seamless footage per extension. It preserves character identity and environmental consistency while natively generating synchronized audio. Multiple extensions can be chained to create cinematic sequences up to 148 seconds in total length.
Fast Version Available
Veo 3.1 Fast is available with the same features as Veo 3.1, except “reference to video”. It offer faster and cheaper generation options:
Was this helpful?